가상 메모리 (Virtual Memory)
물리 메모리보다 더 큰 메모리를 쓰는 기술
1️⃣ 물리 메모리(RAM)보다 더 많은 메모리를 사용할 수 있도록 하는 기법으로, 실제 메모리보다 큰 공간을 제공함.
2️⃣ 디스크의 일부를 “스왑 영역(Swap Space)"로 활용하여 부족한 RAM을 보완함.
3️⃣ 페이지 단위로 메모리를 관리하며, 자주 사용하는 페이지는 RAM에, 덜 쓰는 페이지는 디스크로 이동 (페이지 교체).
4️⃣ 장점: 프로세스당 큰 메모리 공간 사용 가능, 멀티태스킹 효율 증가, 프로그램 간 메모리 보호 제공.
5️⃣ 단점: 디스크 접근 속도가 RAM보다 느려 페이지 폴트(Page Fault)가 많아지면 성능 저하 발생. 🚀
물리주소와 논리 주소
- 물리 주소(physical address) : 하드웨어 상 실제 주소
- 논리 주소(logical address) : CPU가 생성한 주소로, 가상 메모리에서의 위치를 나타내며 물리 주소로 변환(MMU)되어 실제 메모리에 매핑됨.
- 프로세스마다 부여되는 0번지부터 시작되는 주소 체계
- EX ) 현재 메모리 상에 웹 브라우저,메모장,게임 프로세스가 적재 → 이 모든 프로세스에는 0번지부터 시작하는 각자의 논리주소를 가지고 있는 셈
- 중복되는 논리주소의 번지수는 얼마든지 존재할 수 있음.(물리 X)
- 하지만 실제로 정보가 저장되어 있는 하드웨어 상의 메모리와 상호작용하기 위해선
- 반드시 논리 주소와 물리 주소간의 변환이 이루어져야 한다.
그래서 존재하는 하드웨어가 바로 **메모리 관리장치(Memory Management Unit)**다.

스와핑과 연속 메모리 할당
스와핑
✅ 스왑(Swap)의 개념 정리
1️⃣ 스왑은 RAM이 부족할 때, 실행 중인 프로세스의 일부 또는 전체를 디스크(스왑 영역)로 옮겨 RAM을 확보하는 과정
2️⃣ **오랫동안 사용하지 않은 프로세스(비활성 프로세스)**를 스왑 영역으로 내보내고, 필요한 프로세스를 RAM으로 불러와 실행할 수 있도록 함.
3️⃣ CPU가 실행 중인 프로세스는 무조건 RAM에 있어야 하므로, 스왑된 프로세스가 다시 필요해지면 다시 RAM으로 로드해야 해.
4️⃣ 단점: 디스크 속도가 RAM보다 훨씬 느려서, 스왑이 너무 자주 발생하면 시스템 성능이 심각하게 저하됨 (스레싱, Thrashing).
5️⃣ 정리: 스왑은 안 쓰는 프로세스를 임시로 디스크로 옮겼다가, 필요하면 다시 불러오는 작업
- 스왑 영역(Swap Area) : RAM이 부족할 때 디스크의 일부를 가상 메모리로 사용하는 공간
- 보조저장장치임(ssd , hdd 등)
- 스와핑(Swapping) : 프로세스를 통째로 스왑 영역으로 옮겼다가 다시 RAM으로 가져오는 과정.
- 스왑 아웃(Swap-out) : 현재 실행되지 않는 프로세스가 스왑 영역으로 감
- 스왑 인(Swap-in) : 스왑 영역에 있는 프로세스 → 다시 메모리로
연속 메모리 할당과 외부 단편화
✅ 연속 메모리 할당 (Contiguous Memory Allocation)
1️⃣ 프로세스가 실행될 때, 연속된(끊기지 않은) 메모리 공간을 할당하는 방식.
2️⃣ 메모리 공간이 **고정 분할(Fixed Partitioning) 또는 가변 분할(Variable Partitioning)**으로 나뉠 수 있음.
3️⃣ 장점: 관리가 단순하고, 프로세스가 메모리에서 연속적으로 배치되어 접근 속도가 빠름.
4️⃣ 단점: 메모리 조각화(Fragmentation) 발생 (사용할 수 없는 작은 조각들이 생기는 현상)
→외부 단편화 발생 - 작은 빈 공간이 많아지고, 새 프로세스가 할당되기 어려울 수 있음.
5️⃣ 해결책: 압축(Compaction) 기법을 사용하여 조각난 메모리를 정리하거나, 페이징/세그멘테이션 방식으로 전환.
✅ 외부 단편화 (External Fragmentation)
- 메모리 외부
- 설명: 메모리에 빈 공간(홀, Hole)이 존재하지만, 이 공간들이 서로 떨어져 있어서 새로운 프로세스가 사용할 수 없는 상황
✅ 내부 단편화 (Internal Fragmentation)
- 메모리 내부
- 설명: 할당된 메모리 블록 내부에서 실제로 필요한 것보다 더 많은 공간이 주어져서 낭비되는 현상
페이징을 통한 가상 메모리 관리
스와핑(램 <→ ssd) 과 연속 메모리 할당은 두가지 문제를 내포한다.
- 외부 단편화
- 물리 메모리보다 큰 프로세스를 실행할 수 없다. ex) 4기가 메모리 컴퓨터 → 4.1기가 프로그램 실행불가
이러한 문제는 해결하는 운영체제의 메모리 관리 기술이 가상 메모리다.
가상메모리
실행하고자 하는 프로그램의 일부만 메모리에 적재 → 실제 메모리보다 더 큰 프로세스를 실행할 수 있도록 만드는 메모리 기법
페이징과 세그멘테이션이 있음.
- 가상주소공간(virtual address space)이란? 가상 메모리 기법으로 생성된 논리 주소 공간
페이징(가상 메모리 기법 1) - 외부단편화 발생 X
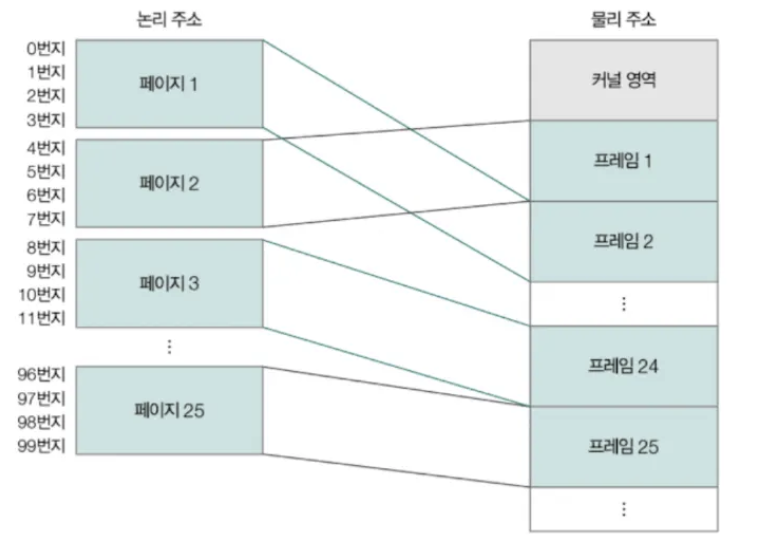
- 프로세스의 논리 주소 공간을 **페이지(page)**라는 단위로 나눔
물리 주소 공간을 페이지와 동일한 크기의 **프레임(frame)**이란 ****단위로 일정하게 나눔
- 페이지를 프레임에 할당하는 가상 메모리 기법
이와 같이 메모리를 할당하면 외부 단편화가 발생하지 않는다.
페이지라는 일정한 크기로 잘린 프로세스들을 메모리에 불연속적으로 할당할 수 있다면 ,
연속 메모리 할당처럼 프로세스 바깥에 빈 공간이 생길 수 없기 때문
페이징에서 스왑 인/아웃
페이징을 사용하는 시스템에선 프로세스 전채가 스왑 아웃/스왑인이 아니라
페이지 단위로 스왑 인/아웃 된다.
이것을 페이지 아웃 / 페이지 인 이라고 부른다.
세그맨테이션(segmentation) - 외부단편화 발생할 수 있음

프로세스를 일정한 크기의 페이지 단위가 아닌 가변적인 크기의 segment 단위로 분할하는 방식
- 나누는 단위가 일정하지 않더라도 유의미한 논리적 단위로 분할하는 방식
- 한 세그먼트는 코드영역(의 일부)일 수도, 데이터 영역(의 일부) 일수도.
- 크기가 일정하지 않아서 외부 단편화가 발생할 수 있다.
프로세스를 구성하는 페이지는 물리 메모리 내에 불연속적으로 배치될 수 있다.
이러면 CPU는 다음 실행할 페이지의 위치를 찾기가 어렵다..

그래서 등장한 게 페이지 테이블임
페이지 테이블 (번역기 역할)
- 가상 주소(Virtual Address) → 물리 주소(Physical Address)로 변환하는 매핑 테이블
- 운영체제(OS)가 각 프로세스마다 별도의 페이지 테이블을 관리
- 페이지 테이블을 통해 프로세스가 연속되지 않은 메모리를 사용할 수 있게 함 (외부 단편화 해결)
📌 구조 예시 (가상 주소 → 물리 주소 변환)
가상 주소 (Virtual Page Number) → 페이지 테이블 → 물리 주소 (Frame Number)
🔷 2. 페이지 테이블 엔트리 (PTE, Page Table Entry)

- 페이지 테이블에 저장된 각 페이지의 정보
- 한 개의 페이지 엔트리(PTE) = 가상 페이지와 매핑된 물리 프레임의 정보
📌 PTE(페이지 엔트리) 주요 정보
필드 설명
| 프레임 번호 (Frame Number) | 해당 페이지가 물리 메모리에서 어느 프레임에 있는지 |
| 보호 비트(protection bit) | 페이지 보호를 위해 존재하는 비트 |
| 유효 비트 (Valid Bit) | 해당 페이지가 현재 메모리에 있는지 (1: 있음, 0: 없음) |
| 페이지 존재 비트 (Present Bit) | 페이지가 물리 메모리에 로드되었는지 (스왑된 경우 0) |
| 읽기/쓰기 비트 (R/W Bit) | 해당 페이지가 읽기/쓰기가 가능한지 여부 |
| 참조 비트 (Reference Bit) | 최근에 사용되었는지 추적 (페이지 교체 알고리즘에 활용) |
| 수정 비트 (Dirty Bit) | 해당 페이지가 수정되었는지 여부 (수정된 경우 디스크에 다시 저장 필요) |
🔥 한 줄 요약
- 페이지 테이블 = 가상 주소를 물리 주소로 변환하는 매핑 테이블
- 페이지 테이블 엔트리 (PTE) = 개별 페이지의 정보(프레임 번호, 읽기/쓰기 권한 등)를 저장하는 항목
- 페이지폴트란?(Page fault) : 프로세스가 접근하려는 페이지가 물리 메모리에 없어서 디스크(스왑 영역)에서 불러와야 하는 상황 , 유효비트가 0인 페이지에서 접근하면 뜸 (예외처리)
👉 PTE를 통해 운영체제는 가상 메모리를 관리하고, 필요하면 페이지 교체를 수행
페이징은 외부단편화 문제를 해결할 수 있지만
내부 단편화라는 문제를 야기한다.
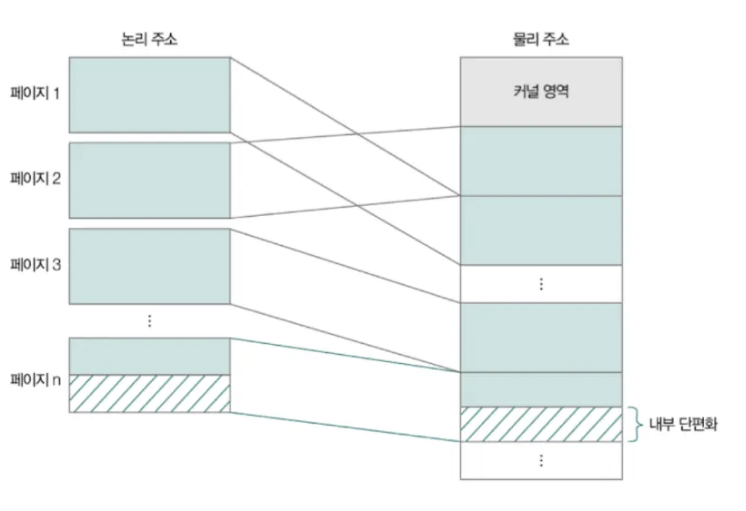
✅ 내부 단편화 (Internal Fragmentation)
1️⃣ 고정 크기 메모리 블록 할당 방식에서, 프로세스가 필요로 하는 메모리보다 더 큰 블록이 할당되면서 남는 공간이 낭비되는 현상
2️⃣ 예: 4KB 블록에서 3KB 크기의 프로세스를 할당하면 1KB가 낭비됨.
3️⃣ 원인: 메모리 블록 크기가 고정되어 있어, 남는 공간을 다른 프로세스가 활용하지 못함.
4️⃣ 해결책: 블록 크기를 최적화하거나, 슬래브 할당(Slab Allocation) 같은 동적 메모리 할당 기법 사용.
5️⃣ 한 줄 요약: "할당된 메모리 내부에서 낭비되는 공간이 생기는 문제."
각 프로세스의 페이지 테이블은 메모리에 적재될 수 있다.
→ 어떤 프로세스 실행하고 싶어 → 프로세스의 페이지 테이블이 메모리에 적재 된 위치를 알아야 한다. → 그 위치를 알려주는게 페이지 테이블 베이스 레지스터다.
페이지 테이블 베이스 레지스터 (네이버지도다.)
Page Table Base Register (PTBR)
CPU가 현재 실행 중인 프로세스의 페이지 테이블 시작 주소를 저장하는 레지스터.
- 프로세스마다 페이지 테이블이 다르므로, 문맥 전환(Context Switch) 시 PTBR을 변경해야 함.
- 가상 주소 → 물리 주소 변환 시, PTBR이 페이지 테이블의 위치를 알려줘 변환 속도를 빠르게 함.
- 페이지 테이블이 커질 경우, **TLB(Translation Lookaside Buffer)**를 사용해 변환 속도를 최적화함.
- 한 줄 요약: "CPU가 참조할 페이지 테이블의 시작 주소를 저장하는 레지스터."
모든 프로세스의 페이지 테이블을 메모리에 두면 비효율적임
길 찾고 싶다 → 모든 경로를 크롬창에 띄워놨어 → 효율적입니까? X
1. 메모리 접근 횟수가 많아진다.
모든 프로세스의 page table이 메모리 적재 시 cpu는 페이지 테이블에 접근하기 위해 총 두번 메모리에 접근해야 함. (1. 페이지 테이블 접근 ,2.실제 프레임 접근) ⇒ 시간이 2배
이를 해결하기 위해 TLB(주소 변환 캐시)를 사용해 자주 사용할 법한 페이지 위주로
페이지 테이블의 일부 내용을 저장함.

✅ TLB (Translation Lookaside Buffer) - 주소 변환 캐시
1️⃣ 페이지 테이블을 빠르게 참조하기 위해 사용하는 캐시 메모리로, 가상 주소 → 물리 주소 변환 속도를 높여줌.
2️⃣ 페이지 테이블을 직접 접근하는 대신, 자주 사용하는 주소 매핑 정보를 TLB에 저장하여 빠르게 검색.
3️⃣ TLB 히트(TLB Hit): 찾으려는 가상 주소가 TLB에 존재하는 경우, 즉 페이지 테이블을 거치지 않고 빠르게 변환됨. (어? 주소 찾음!)
4️⃣ TLB 미스(TLB Miss): TLB에 주소 정보가 없어서 페이지 테이블을 직접 조회해야 하는 경우, 속도가 느려짐. (어? 주소 없네..검색해서 찾아봐야지..)
5️⃣ 한 줄 요약: "페이지 테이블 조회를 빠르게 하기 위한 CPU 캐시 역할을 하는 변환 테이블."
👉 TLB 히트율이 높을수록 주소 변환 속도가 빨라져 성능이 향상됨
2.메모리 용량을 많이 차지한다.
페이지 테이블의 크기는 생각보다 작지 않다.
그래서 등장한 방법 중 하나가 계층적 페이징이다.
계층적 페이징 - 페이지 테이블을 페이징하는 방식
다단계 페이지 테이블 기법이라고도 부름
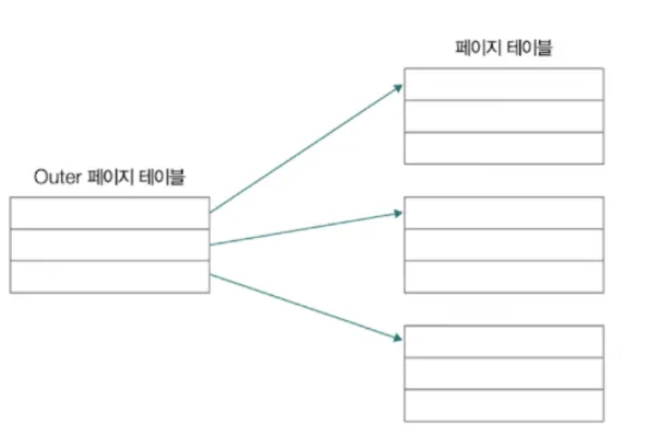
✅ 계층적 페이징 (Hierarchical Paging) - 다단계 페이지 테이블
1️⃣ 페이지 테이블 크기가 너무 커질 경우, 이를 여러 단계로 나누어 관리하는 방식.
2️⃣ 1차(상위) 페이지 테이블이 2차(하위) 페이지 테이블의 주소를 가리키는 구조로, 한 번에 전체 페이지 테이블을 로드하지 않아도 됨.
3️⃣ 메모리 사용량을 줄일 수 있지만, 주소 변환 과정이 여러 번 발생하여 접근 속도가 느려질 수 있음.
4️⃣ 2단계(2-Level), 3단계(3-Level) 등 여러 단계로 구성될 수 있으며, 대형 시스템에서 주로 사용됨.
객체 안에 객체 같은 느낌이다.
페이징 주소 체계 (걍 도로명 주소임)
하나의 페이지 내에 여러 주소가 포함되어 있기 때문에
페이징 시스템의 논리주소는 기본적으로 <페이지번호,변위>와 같은 형태로 되어 있음.
- 페이지 번호 : 몇번째 페이지 번호에 접근할지를 나타냄
- 변위 : 접근하려는 주소가 페이지(프레임) 시작 번지로부터 얼만큼 떨어져 있는지를 나타냄
📌 페이지 주소 체계 = 현실 주소 체계 비교
현실 주소 🏡 페이지 주소 🖥
| 서울특별시 | 상위 페이지 테이블 (Page Directory) |
| 마포구 | 중간 페이지 테이블 (Page Table Level 2) |
| 고산길 | 하위 페이지 테이블 (Page Table Level 3) |
| 30-3번지 | 실제 메모리 프레임 (Physical Frame) |
📌 설명
1️⃣ 서울특별시 → 마포구 → 고산길 → 30-3 순서로 점점 더 구체적인 위치를 찾듯이,
2️⃣ 계층적 페이징도 "상위 페이지 테이블 → 하위 페이지 테이블 → 물리 메모리 프레임" 순서로 찾아감
👉 즉, 페이지 주소 체계는 현실의 주소 체계와 같은 개념이며, 점점 더 세부적인 주소를 따라가면서 원하는 데이터를 찾는 구조! 🚀
페이지 교체 알고리즘
✅ 페이지 교체 알고리즘 (Page Replacement Algorithms)
💡 페이지 교체란?
- 메모리에 빈 공간이 없을 때, 기존 페이지를 내보내고 새로운 페이지를 가져오는 과정
- 요구 페이징(Demand Paging): 필요한 페이지만 메모리에 로드하는 방식 (J)
- 순수 요구 페이징(Pure Demand Paging): 처음부터 메모리에 아무 페이지도 올리지 않고, 필요한 페이지만 불러옴 ( P)
🔥 1. FIFO (First-In-First-Out) 페이지 교체 알고리즘
- 가장 먼저 들어온 페이지를 먼저 내보냄 (Queue 방식)
- 장점: 구현이 간단함
- 단점: 오래된 페이지가 아직 필요할 수도 있어 성능 저하 발생 (Belady’s Anomaly, 벨라디의 모순)
- 예제
- 페이지 요청 순서: [1, 2, 3, 4, 1, 2, 5] (프레임 3개) 1 1 1 1 1 1 5 2 2 2 2 2 2 3 3 3 3 3 교체: 3이 제거됨
🔥 2. OPT (Optimal, 최적 페이지 교체 알고리즘)
- 가장 나중에 다시 사용될 페이지를 제거 (이론적으로 가장 적은 페이지 폴트 발생)
- 장점: 가장 효율적인 알고리즘
- 단점: 미래의 페이지 요청을 미리 알아야 해서 실제 구현이 불가능함 (이론적 비교용)
- 예제
- 페이지 요청 순서: [1, 2, 3, 4, 1, 2, 5] (프레임 3개) 1 1 1 1 1 1 5 2 2 2 2 2 2 3 3 4 4 4 교체: 3이 나중에 다시 사용되지 않으므로 제거됨
🔥 3. LRU (Least Recently Used) 페이지 교체 알고리즘
- 가장 오랫동안 사용되지 않은 페이지를 제거
- 장점: 실제로 자주 쓰이는 페이지를 유지할 수 있어 성능이 좋음
- 단점: 사용 이력을 추적해야 해서 구현이 복잡하고 오버헤드 발생
- 예제
- 페이지 요청 순서: [1, 2, 3, 4, 1, 2, 5] (프레임 3개) 1 1 1 1 1 1 5 2 2 2 2 2 2 3 3 4 4 4 교체: 가장 오래 사용되지 않은 3이 제거됨
🔥 요약 비교표
알고리즘 방식 장점 단점
| FIFO | 먼저 들어온 페이지 제거 | 구현 간단 | 오래된 페이지가 여전히 필요할 수도 있음 (Belady's Anomaly) |
| OPT | 미래에 가장 늦게 사용될 페이지 제거 | 가장 적은 페이지 폴트 발생 (이론적 최적) | 미래를 알아야 해서 실제 구현 불가능 |
| LRU | 가장 오래 사용되지 않은 페이지 제거 | 실제 사용 패턴을 반영 | 사용 이력 추적 필요 (오버헤드 발생) |
✅ 한 줄 요약
- FIFO → 들어온 순서대로 제거 (오래됐다고 안 쓰는 게 아님 😭)
- OPT → 가장 나중에 다시 사용될 페이지 제거 (이론적으로 최고지만 현실 불가 🤯)
- LRU → 가장 오래 사용 안 된 페이지 제거 (현실적이고 성능 좋음 👍)
👉 운영체제는 보통 FIFO 대신 LRU 또는 LRU 근사 알고리즘을 사용함! 🚀
페이지 폴트(Page fault)
프로세스가 참조하려는 페이지가 현재 메모리(RAM)에 없을 때 발생하는 이벤트.
✅ 메이저 페이지 폴트 (Major Page Fault)
- 페이지가 물리 메모리에 없어서 디스크(스왑 영역)에서 불러와야 하는 경우 → 속도가 느림.
- 디스크에서 데이터를 읽어야 하므로 큰 성능 저하 발생 (I/O 오버헤드).
✅ 마이너 페이지 폴트 (Minor Page Fault)
- 페이지가 물리 메모리에 있지만, 프로세스의 페이지 테이블에 매핑되지 않은 경우.
- 디스크 접근 없이 매핑만 갱신하면 되므로 성능 영향이 적음.
'Study > CS' 카테고리의 다른 글
| 4.1 ~ 4.4 자료구조 (1) | 2025.02.26 |
|---|---|
| 03 - 6 파일 시스템 (0) | 2025.02.19 |
| 03 - 4 CPU 스케줄링 (0) | 2025.02.19 |
| 03-3 동기화와 교착 상태 (0) | 2025.02.12 |
| 03-2 프로세스와 스레드 (1) | 2025.02.12 |



