RAM
전원을 끄면 저장하고 있던 데이터와 명령어가 날아가는 휘발성 저장장치
RAM은 임시접근 메모리다.
RAM - 임시접근메모리(Random Access Memory)의 약자
임의 접근이란? : 저장된 요소에 순차적으로 접근할 필요 X → 임의 위치로 곧장 접근 OK
순차 접근이란? : 1,~100번까지 접근
1. DRAM (Dynamic RAM)
- 동적인 말 그대로 데이터가 동적으로 변하는(사라지는 특성을 의미)
- 시간이 지나면 저장된 데이터가 점차 사라지는 램이다.
- 데이터 소멸을 막기 위해 일정 주기로 데이터를 다시 저장해야 한다.
- 소비 전력 good , 저렴 , 집적도가 높음
2.SRAM(Static RAM)
- DRAM과 달리 저장된 데이터가 변하지 않는 RAM을 의미한다.
- 비휘발성이란 말은 아님. 전원 공급되지 않으면 내용 소실
- 속도 high , 소비전력 bad , 비쌈, 집적도가 낮음
- 캐시 메모리에 쓴다.
3. SDRAM (Synchronous DRAM)
- 동기식 DRAM으로, CPU 클럭에 맞춰 동기화되어 작동
- 빠른 데이터 전송 속도를 제공하고, 버스 속도에 맞춰 동작
- 일반적인 DRAM보다 성능이 높고, 주로 컴퓨터 메모리로 사용
- 가격 low, 소비 전력 good
4. DDR SDRAM (Double Data Rate SDRAM)
- DDR SDRAM은 데이터를 두 번 전송하는 방식으로 속도를 2배 향상시킨 Synchronous DRAM이다.
- 빠른 속도로 게임, 그래픽 작업 등 고속 데이터 전송이 필요한 곳에 사용
- DDR2, DDR3, DDR4와 같은 다양한 버전이 있으며, 버전이 높을수록 속도와 효율이 향상
- 가격이 일반 DRAM보다는 높지만, 성능이 뛰어나고 전력 효율 good
메모리에 바이트를 밀어 넣는 순서 - 빅 엔디안과 리틀 엔디안
*빅 엔디안 (Big Endian)**과 **리틀 엔디안 (Little Endian)**은 바이트 순서를 정의하는 방식이다.
메모리에 데이터를 저장할 때, 여러 바이트로 이루어진 값을 어떻게 배열할지에 대한 규칙
1. 빅 엔디안 (Big Endian):
- *가장 중요한 바이트(MSB, Most Significant Byte)**가 메모리의 가장 낮은 주소에 저장된다.
- 예를 들어, 4바이트 데이터 0x12345678을 저장할 때:
- 메모리 순서는 12 34 56 78로 저장된다. (첫 번째 바이트가 가장 큰 값)
2. 리틀 엔디안 (Little Endian):
- *가장 중요한 바이트(MSB)**가 메모리의 가장 높은 주소에 저장된다.
- 예를 들어, 4바이트 데이터 0x12345678을 저장할 때:
- 메모리 순서는 78 56 34 12로 저장된다. (첫 번째 바이트가 가장 작은 값)
요약:
- 빅 엔디안: 가장 큰 바이트부터 시작하여 작은 바이트 순으로 저장.
- 리틀 엔디안: 가장 작은 바이트부터 시작하여 큰 바이트 순으로 저장.
캐시 메모리
CPU의 연산 속도와 메모리 접근 속도의 차이를 줄이기 위해 탄생한 저장장치
CPU와 메모리 사이에 위치한 SRAM 기반의 저장장치다.

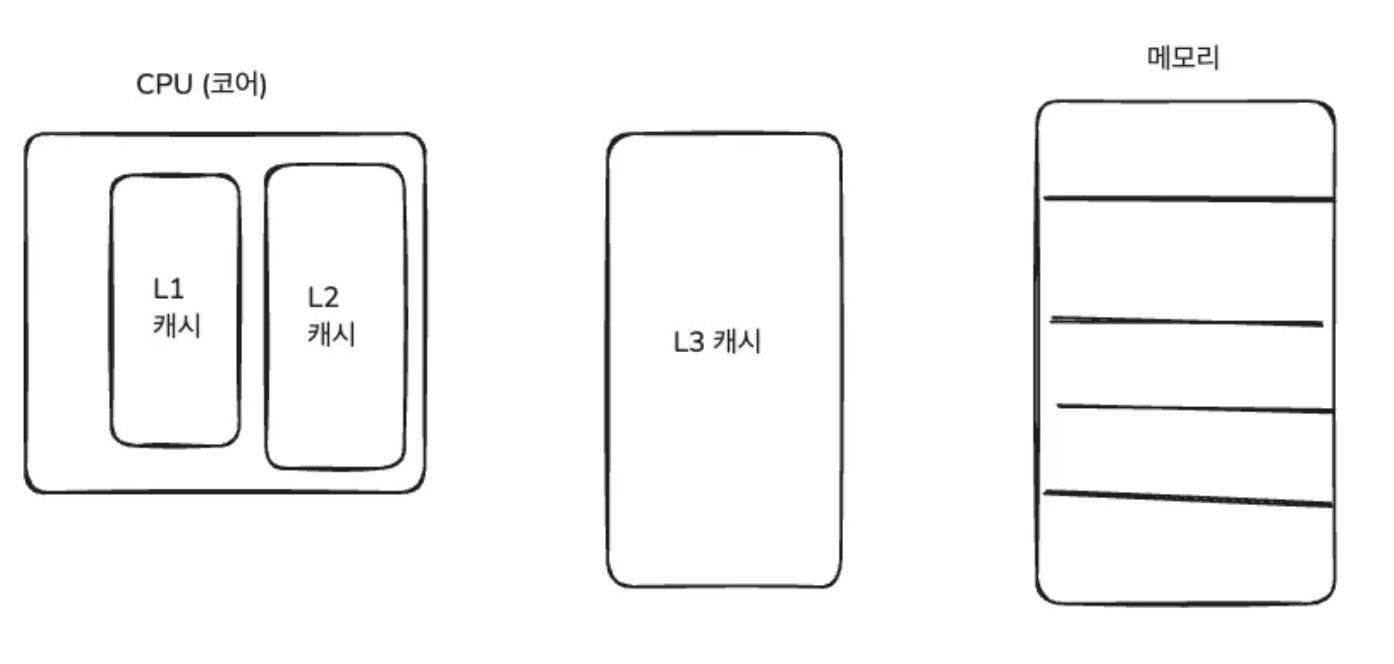
캐시 메모리
- L1 : 코어랑 가장 가까운 캐시 메모리 (내부)
- L2 : 코어랑 두번째로 가까운 캐시 메모리 (내부)
- L3 : 코어랑 세번째로 가까운 캐시 메모리 ( 외부)
- 캐시 메모리 크기 : L1 < L2 < L3
- 캐시 메모리 속도 : L3 < L2 < L1
🎯 분리형 캐시 vs 통합형 캐시
- 분리형 캐시
- L1처럼 명령어 캐시(L1I)와 데이터 캐시(L1D)가 따로 있는 구조.
- 명령어와 데이터를 따로 관리하니까 CPU가 빠르게 가져올 수 있음.
- 통합형 캐시
- L2/L3처럼 명령어+데이터가 같이 저장됨.
- 공간 활용 효율이 좋고, 공유 가능함.

레벨 속도 용량 저장하는 것 특징 위치(CPU)
| L1 | 가장 빠름 | 작음 (32KB~128KB) | 자주 쓰는 명령어 & 데이터 | 코어별 개별 존재, 분리형(L1I, L1D) | 내부 |
| L2 | 빠름 | 중간 (512KB~2MB) | L1에서 밀려난 데이터 | 코어별 개별 존재 or 공유 가능 | 내부 |
| L3 | 느림 | 큼 (4MB~64MB) | CPU 전체가 공유하는 데이터 | 여러 코어가 공유 | 외부 |
🎯 캐시 히트(Cache Hit) - "야! 찾았다!"
CPU가 필요한 데이터를 캐시에서 바로 찾은 경우!
✅ 캐시에서 데이터가 바로 나오니까 속도가 빠름.
✅ RAM까지 안 가도 돼서 전력 소모 적음.
📌 예시
- CPU가 x = x + 1 연산을 수행하려고 하는데, x 값이 L1 캐시에 있음.
- CPU가 L1 캐시에서 바로 가져와서 연산!
- 속도가 개빠름! 🚀 (1~4 사이클 이내 처리)
❌ 캐시 미스(Cache Miss) - "없네? 찾으러 가야겠다..."
CPU가 데이터를 캐시에서 찾으려고 했는데 없어서 더 느린 곳에서 가져와야 하는 경우.
❌ L1, L2, L3에도 없으면 결국 RAM에서 가져와야 해서 속도 저하됨.
❌ RAM보다 느린 SSD나 HDD에서 데이터를 가져오면 더 오래 걸림.
📌 예시
- CPU가 y = y + 1 연산하려는데, y 값이 캐시 어디에도 없음.
- 결국 RAM에서 데이터를 가져와야 함. (이 과정이 느림)
- 가져온 데이터는 캐시에 저장해서 다음번에 캐시 히트가 될 확률을 높임.
🚀 캐시 히트율(Cache Hit Ratio) - 성능 핵심 지표
- 캐시에서 데이터를 찾는 비율이 높을수록 CPU 성능이 잘 나옴.
- 캐시 히트율 = (캐시 히트 횟수) / (전체 요청 횟수) × 100%
- 보통 캐시 히트율이 90% 이상이면 최적화가 잘 된 상태.
✅ 캐시 히트율이 높으면 → 성능 좋음, 빠름, 전력 소모 적음.
❌ 캐시 히트율이 낮으면 → 성능 저하, RAM 과부하, 전력 소모 많음.
🎯 캐시 미스의 종류
캐시 미스도 몇 가지 이유가 있음.
1️⃣ Cold Miss (Cold Start Miss) - "처음이라 그래요..."
- 캐시가 처음 비었을 때 발생.
- 프로그램 실행 초기에는 어쩔 수 없이 발생함.
2️⃣ Capacity Miss - "자리 부족해요!"
- 캐시 용량이 작아서 오래된 데이터가 사라지고, 다시 필요할 때 RAM에서 가져와야 하는 상황.
- L1, L2, L3 캐시 용량이 작은 CPU에서 자주 발생.
3️⃣ Conflict Miss - "자리 있는데 못 들어가요!"
- 캐시에서 특정 위치만 써야 하는데, 이미 다른 데이터가 있어서 덮어씌워야 하는 경우.
- 캐시 구조 최적화가 잘못되면 이런 문제가 자주 발생.
💡 정리
개념 뜻 결과
| 캐시 히트 | CPU가 캐시에서 원하는 데이터를 찾음 | ✅ 빠름, 성능 좋음 |
| 캐시 미스 | CPU가 캐시에서 못 찾고 RAM까지 감 | ❌ 느림, 성능 저하 |
🔥 한 줄 요약
- 캐시 히트 → 데이터 바로 찾음 → 개빠름
- 캐시 미스 → 데이터 못 찾음 → RAM까지 감 → 느림
- 캐시 히트율 높이는 게 CPU 성능 최적화의 핵심! 🔥
🎯 참조 지역성이란?
CPU나 프로그램이 메모리를 접근할 때, 특정 패턴이 반복적으로 나타나는 성질을 말함.
➡ 즉, 최근에 접근한 데이터나 코드에 다시 접근할 확률이 높다!
이걸 잘 활용하면 캐시 메모리를 최적화해서 속도를 확 끌어올릴 수 있음.
💡 참조 지역성의 종류
참조 지역성에는 크게 **시간 지역성(Temporal Locality)**과 공간 지역성(Spatial Locality) 두 가지가 있음.
🔥 1. 시간 지역성(Temporal Locality) - "방금 쓴 거 또 쓸 확률 높음"
- CPU가 최근에 접근한 데이터나 명령어는 곧 다시 접근할 가능성이 높음.
- 그래서 캐시에 저장해두면 캐시 히트율이 올라감!
📌 예시:
- for 루프에서 i 값을 계속 사용함
- for (int i = 0; i < 1000; i++) { sum += arr[i]; // i가 계속 사용됨 (시간 지역성 있음
- 함수 호출 시에도 적용됨
- int sum(int a, int b) { return a + b; // sum() 함수는 여러 번 호출될 가능성 높음 (시간 지역성 있음) }
- 자주 사용하는 변수, 함수는 캐시에 저장해두면 성능 UP!
🚀 2. 공간 지역성(Spatial Locality) - "가까운 데이터도 같이 쓸 확률 높음"
- CPU가 특정 위치의 데이터를 읽으면, 그 근처의 데이터도 곧 접근할 확률이 높음.
- 그래서 CPU는 데이터를 가져올 때, 한 번에 여러 개 묶어서 캐시에 저장함.
📌 예시:
- 배열을 순차적으로 접근할 때→ 배열은 메모리에 연속적으로 저장되기 때문에, 캐시에 한 번에 로딩됨.
- for (int i = 0; i < 1000; i++) { sum += arr[i]; // arr[i]를 사용하면, arr[i+1]도 곧 사용할 확률 높음 }
- 2D 배열을 순차적으로 읽을 때 (행 우선 순회)→ 이렇게 하면 캐시 효율이 좋아짐!
- (반대로 matrix[j][i]처럼 열 우선 순회하면 캐시 미스가 증가할 수도 있음.)
- for (int i = 0; i < 100; i++) { for (int j = 0; j < 100; j++) { sum += matrix[i][j]; // 같은 행을 연속적으로 읽으니까 공간 지역성 있음! } }
🔥 3. 순차 지역성(Sequential Locality) - "순서대로 접근하면 효율 UP!"
- CPU가 데이터를 순서대로 읽을 때 성능이 좋아지는 성질.
- 공간 지역성과 비슷하지만, 특히 순차 접근에서 효과적임.
📌 예시:
for (int i = 0; i < 1000; i++) {
sum += arr[i]; // 순차적으로 접근하니까 캐시 효율 극대화!
}
- 배열을 랜덤으로 접근하는 것보다, 순차적으로 접근하는 게 훨씬 빠름.
- 그래서 리스트보다는 배열이 캐시 효율이 좋음!
🏎 CPU 캐시 최적화와 참조 지역성
참조 지역성을 잘 활용하면 CPU 캐시 효율이 올라가고, 성능이 대폭 향상됨.
그래서 프로그래밍할 때 배열 순차 접근이나 자주 쓰는 함수 최적화가 중요한 거임!
✅ 최적화 방법
- 배열을 순차적으로 접근하라!→ for (int i = n-1; i >= 0; i--) {} 이렇게 해도 괜찮음!
- → for (int i = 0; i < n; i++) {} 이렇게 하면 캐시 히트율 UP!
- 자주 쓰는 변수는 캐시에 저장되도록 유지하라!
- → 반복적으로 호출하는 함수는 따로 최적화!
- 메모리 할당을 연속적으로 하라!
- → std::vector 같은 동적 배열이 std::list보다 빠른 이유도 공간 지역성 때문!
🎯 정리: 참조 지역성이 중요한 이유
지역성 종류 의미 예시 최적화 방법
| 시간 지역성 | 최근에 사용한 데이터는 또 사용될 확률 높음 | 같은 변수 여러 번 접근 | 자주 쓰는 변수는 캐시에 유지 |
| 공간 지역성 | 특정 위치의 데이터를 읽으면, 그 근처도 곧 접근함 | 배열, 메모리 블록 | 순차 접근이 빠름 |
| 순차 지역성 | 연속된 데이터 접근이 빠름 | for문에서 배열 순회 | 랜덤 접근보다 순차 접근 사용 |
🔥 한 줄 요약
👉 "최근에 사용한 데이터는 또 쓰이고, 가까운 데이터도 같이 쓰인다!"
👉 "그래서 캐시에 데이터를 잘 저장하면 성능이 개빨라진다!" 🚀
🔥 캐시 메모리의 쓰기 정책(Cache Write Policy)
CPU가 데이터를 캐시에 저장할 때 RAM과의 동기화 방식에 따라 두 가지 방식이 있음.
- Write-Through (즉시 쓰기)
- 캐시와 RAM에 동시에 저장 → 데이터 일관성 유지
- RAM 접근이 많아 느림, 전력 소모 큼
- 서버, 데이터베이스에 적합
- Write-Back (지연 쓰기)
- 캐시에만 저장 후 나중에 RAM 업데이트
- 속도 빠름, 전력 효율 좋음
- 게임, 그래픽 처리에 적합
- 단, 데이터 손실 위험 있음
🚀 캐시 일관성(Cache Coherency)
멀티코어 CPU에서는 같은 데이터가 여러 캐시에 저장되면 동기화 문제 발생 가능 → 해결책 필요!
- 스누핑(Snooping): 모든 코어가 버스를 감시해 데이터 변경 감지
- 디렉터리 기반(Coherency Directory): 중앙에서 캐시 일관성 관리
✅ 정리
- Write-Through → RAM까지 바로 저장 (안정적, 느림)
- Write-Back → 캐시에만 저장 후 나중에 RAM 반영 (빠름, 위험)
- 캐시 일관성 → 멀티코어 CPU에서 데이터 동기화 문제 해결
'Study > CS' 카테고리의 다른 글
| 03-2 프로세스와 스레드 (1) | 2025.02.12 |
|---|---|
| 03-1 운영체제 큰그림 (0) | 2025.02.12 |
| 02-5 보조기억장치와 입출력 장치 (0) | 2025.02.05 |
| 02-3 CPU (0) | 2025.02.05 |
| 02.컴퓨터 구조 (2) | 2025.01.22 |



